1.连接数据库 1 mysql (- h IP) - u root - p 密码
2.查看数据库 3.使用数据库 4.查看表 1 show tables [from db_name]
5.查看表结构 6.创建、删除、选择数据库 1 2 3 4 5 create database db_namedrop database db_nameuse db_name
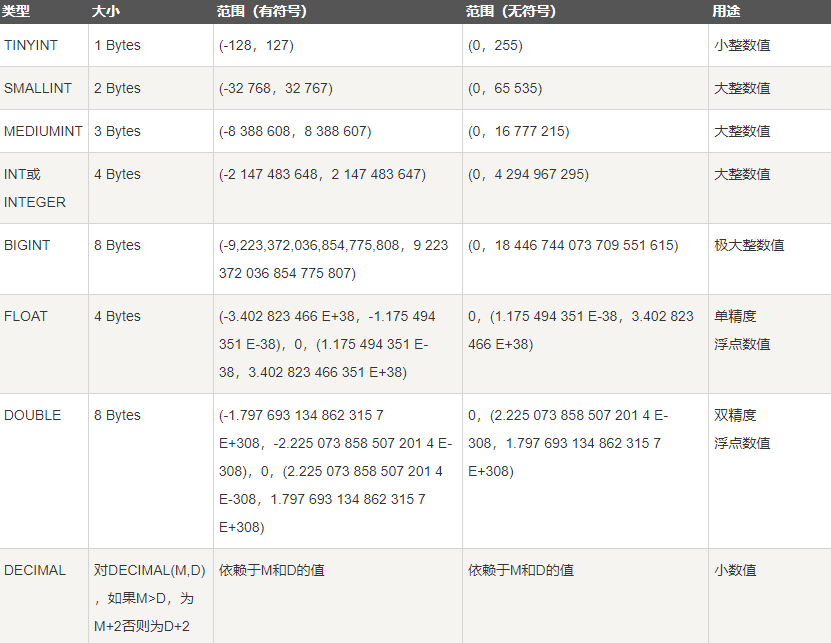
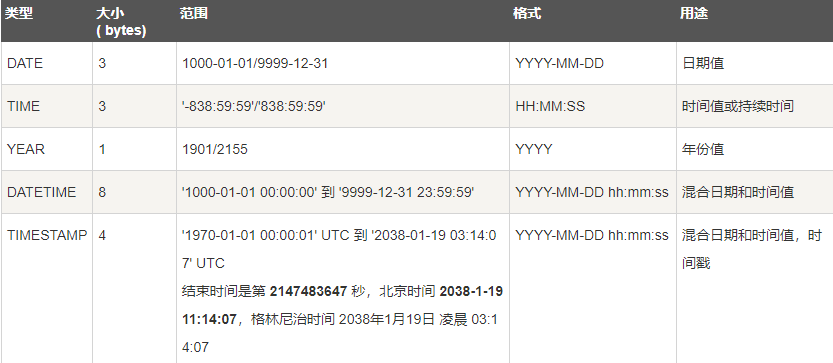
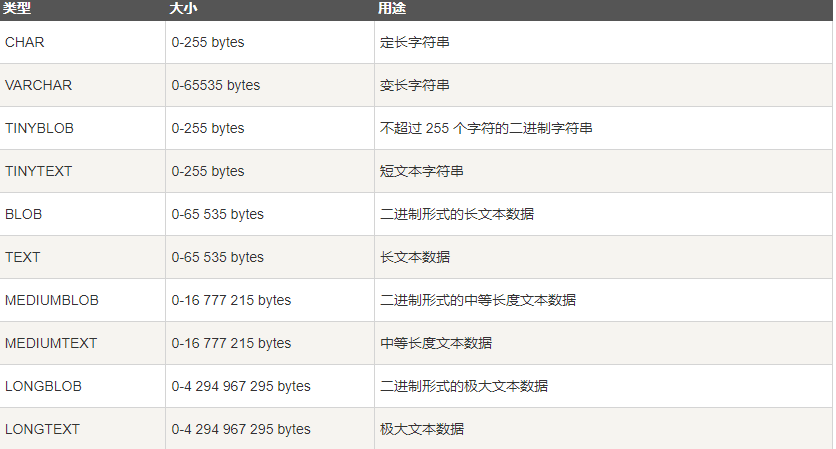
7.数据类型 参考链接:https://www.runoob.com/mysql/mysql-data-types.html
● 字符串类型
8.创建、删除数据表 1 2 3 4 5 6 7 8 9 10 create table [if not exsits] tb_name ( `id` INT UNSIGNED AUTO_INCREMENT, `title` VARCHAR (100 ) NOT NULL , `author` VARCHAR (40 ) NOT NULL , `submission_date` DATE , PRIMARY KEY ( `id` ) ) default charset= utf8; drop table tb_name
9.插入、查询、修改、删除数据 1 2 3 4 5 6 7 8 9 10 11 insert into tb_name (field1, field2,...,fieldN) values (value1, value2,...valueN) select * from tb_name select field1, field2,... from tb_name [where ...] [limit n] [offset m] select field1,field2,... from tb_name1, tb_name2,... [where condition1 and / or condition2 ...]update tb_name set field1= xxx, fieldn= xxx [where caluse]delete from tb_name [where clause]
10.like子句 1 2 3 SELECT * from tb_name WHERE author LIKE '%COM'
11.注释 12.union 1 2 3 4 5 select expression1, expression2, ... expression_n from tb_name1 [where conditions]UNION [ALL | DISTINCT ] select expression1, expression2, ... expression_n from tb_name2 [where conditions];
13.排序 1 2 3 4 5 select field1, ...,fieldn from tb_name [where clause] [order by field1 [asc ], field2 desc ]
14.分组 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 select column_name, function (column_name) from tb_name [where clause] group by column_nameselect column_name1, function (column_name2) from tb_name [where clause] group by column_name [with rollup ]select coalesce (a,b,c);SELECT coalesce (name, '总数' ), SUM (signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP ;
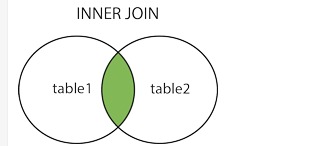
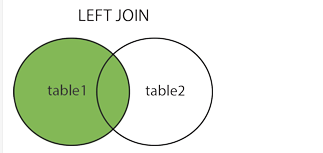
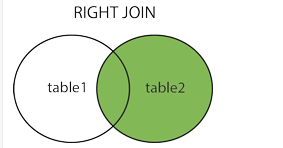
15.连接 1 2 3 4 5 6 7 8 9 10 select field1 from tb_name1 a inner join tb_name1 b on a.field2 = b.field3 select field1 from tb_name1 a left join tb_name1 b on a.field2 = b.field3select field1 from tb_name1 a right join tb_name1 b on a.field2 = b.field3
16.NULL的处理 不能使用 = NULL 或 != NULL 在列中查找 NULL 值
1 2 3 4 5 6 7 select * from tb_name where field1 is null select * from tb_name where field1 is not null
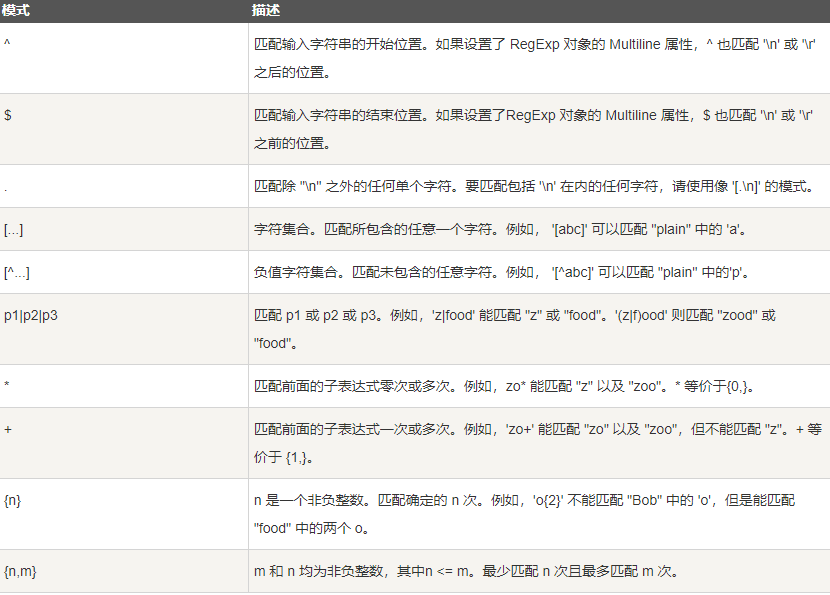
17.正则表达式 1 2 3 SELECT * FROM tb_name WHERE field REGEXP '^xxx' ;
18.事务 事务控制语句
1.用 BEGIN, ROLLBACK, COMMIT来实现 ● BEGIN 开始一个事务
2.直接用 SET 来改变 MySQL 的自动提交模式: ● SET AUTOCOMMIT=0 禁止自动提交
1 2 3 4 5 begin ... commit (rollback )
19.ALTER命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 alter table tb_name add new_field_name data_typealter table tb_name modify field_name new_data_type alter table tb_name change old_field_name new_field_name data_type alter table tb_name drop field_namealter table tb_name add primary key (field_name) alter table tb_name add foreign key (field_name) references referenced_tb (reference_field_name) alter table tb_name add constraint constraint_name unique (field_name) alter table tb_name add index index_name(field_name1 [asc | desc ],field_name2 [asc | desc ] ,...) alter table tb_name add unique index index_name(field_name1 [asc | desc ],field_name2 [asc | desc ] ,...) alter table tb_name drop index index_name alter table tb_name rename to new_tb_namealter table tb_name engine= new_storage_engine
20.索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 create [unique ] index index_name on tb_name (ield_name1 [asc | desc ],field_name2 [asc | desc ] ,...) alter table tb_name add [unique ] index index_name(field_name1 [asc | desc ],field_name2 [asc | desc ] ,...) create table tb_name ( ... index index_name [unique ] (field_name1 [asc | desc ],field_name2 [asc | desc ] ,...) ) drop index index_name on tb_namealter table tb_name drop index index_nameshow index from tb_name
21.临时表 1 2 create temporary table tb_name (...)
22.复制表 1 2 3 4 5 6 7 8 show create table tb_nameinsert into clone_tb (...) select (...) from origin_tb
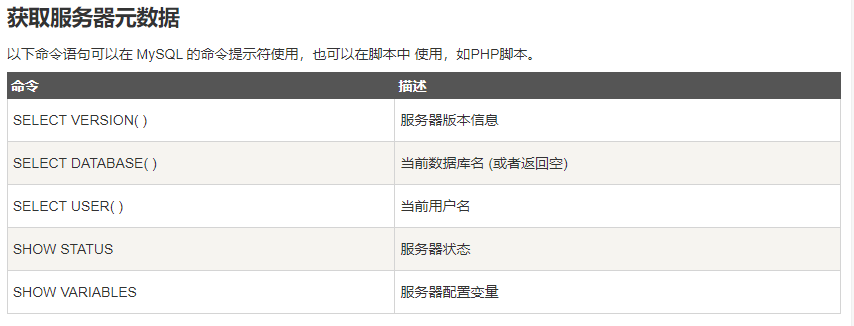
23.元数据
24.序列使用 25.处理重复数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 primary keyunique select count (* ) as xx, filed1, field2 from tb_name group by field1,field2 having xx > 1 select distinct field from tb_name
26.导出、导入数据 1 2 3 4 5 6 7 8 9 select * into outfile '地址' [fields terminated by ',' optionally enclosed by '"' lines terminated BY '\n' ] from tb_namesource '地址' load data local infile '地址' into table tb_name
27.函数、运算符 函数:https://www.runoob.com/mysql/mysql-functions.html https://www.runoob.com/mysql/mysql-operator.html